

Big Data, Natural Language Processing, Sentiment Analysis, Data Sciences, and Predictive Analytics are the talk of the town and it doesn’t matter which town you are referring to, it’s everywhere, from the United Nations using predictive analytics to forecast bombings on schools to companies using Kaggle to launch their own competitions. There are dozens of Startups springing out every month stretching human imagination of how the underlying technologies can be used to improve our lives and everything we do.
Data science is in demand and its growth is on steroids. According to Linkedin, “Statistical Analysis” and “Data Mining” are two top-most skills to get hired this year. Gartner says there are 4.4 million jobs for data scientists (and related titles) worldwide, 1.9 million in the US alone. One data science job creates another three non-IT jobs, so we are talking about some 13 million jobs altogether. The question is what YOU can do to secure a job and make your dreams come true, and how YOU can become someone that would qualify for these 4.4 million jobs worldwide.
There are at least 50 data science degree programs by universities worldwide offering diplomas in this discipline, it costs from 50,000 to 270,000 US$ and takes 1 to 4 years of your life. It might be a good option if you are looking to join college soon, and it has its own benefits over other programs in similar or not-to-so similar disciplines. I find these programs very expensive for the people from developing countries or working professionals to commit X years of their lives.
Then there are few very good summer programs, fellowships and boot camps that promise you to make a data scientists in very short span of time, some of them are free but almost impossible to get in, while other requires a PhD or advanced degree, and some would cost between 15,000 to 25,000 US$ for 2 months or so. While these are very good options for recent Ph.D. graduates to gain some real industry experience, we have yet to see their quality and performance against a veteran industry analyst. Few of the ones that I really like are Data Incubator, Insight Fellowship, Metis Bootcamp, Data Science for Social Goods , Intel AI Academy, and the famous Zipfian Academy programs.
Let me also mention few paid resources that I am a fan of before I tell you how to do all that for free. First one is the Explore Data Science program by Booz Allen, it costs 1,250 $ but worth every single penny. Second one is recorded lectures by Tim Chartier on DVD, called Big Data: How Data Analytics is transforming the world, it costs 80 bucks and worth your investment. The next in the list are two courses by MIT, Tackling the Big Data Challenges, that costs 500$ and provides you a very solid theoretical foundation on big data, and The Analytics Edge, that costs only 100 bucks and gives a superb introduction on how the analytics can be used to solve day-to-day business problems. If you can spare few hours a day then Udacity offers a perfect Nanodegree for Data Analysts that costs 200$/month can be completed in 6 months or so, they offer this in partnership with Facebook, Zipfian Academy, and MongoDB. ThinkFul has a wonderful program for 500$/month to connect you live with a mentor to guide you to become a data scientist. You don’t want to miss the DataCamp’s Data Science with Python Track and the Deep Learning Specialization at Coursera too.
Ok, so what one can do to become a data scientist if he/she cannot afford or get selected in the aforementioned competitive and expensive programs. What someone from a developing country like Pakistan can do to improve his/her chances of getting hired in this very important field or even try to use these advanced skills to improve their own surroundings, communities and countries.
Here is my cheat sheet of becoming a Data Scientist for Free:
- Understand Data: Data is useless and can (and should) be misleading without the context. Data needs a story to tell a story. Data is like a color that needs a surface to even prove its existence, as color red for example, cannot prove its existence without a surface – we see a red car, or red scarf, red tie, red shoes or red something – similarly data needs to be associated with its surroundings, context, methods, ways and the whole life cycle where it is born, generated, used, modified, executed and terminated. I have yet to find a “data scientist” who can talk to me about the “data” without mentioning technologies like Hadoop, NoSQL, Tableau or other sophisticated vendors and buzzwords. You need to have an intimate relationship with your data; you need to know it inside out. Asking someone else about anomalies in “your” data clearly means you have no idea how your data in being generated, recorded or need to be analyzed in the first place.
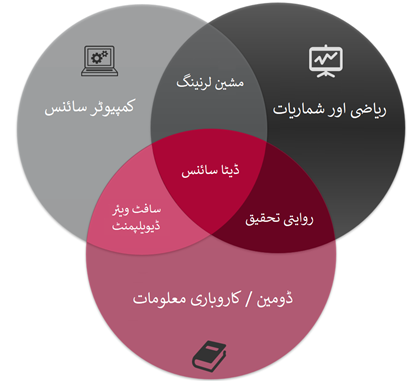
- Understand Data Scientist: Unfortunately, one of the most confused and misused word in data sciences filed is the “data scientist” itself. Someone relate it to a mystic oracle who would know everything under the sun, while others would reduce it down to statistical expert, for few its someone familiar with Hadoop and NoSQL, and for others it is someone who can perform A/B testing and can use so much mathematics and statistical terms that would be hard to understand in executive meetings. For some, it is visualization dashboards and for others it’s a never ending ETL processes. For me, a Data Scientist is someone who understands less about the science than the ones who creates it and little less about the data than the ones who generates it, but exactly knows how these two works together. A good data scientist is the one who knows what is available “outside the box” and who he needs to connect with, hire, or the technologies he needs to deploy to get the job done, one who can link business objectives with data marts, and who can simply connect the dots from business gains to human behaviors and from data generation to dollars spent.
- Watch these 13 Ted Videos
- Watch this video of Hans Rosling to understand the power of Visualization
- Listen to weekly podcasts by Partially Derivative on Data Sciences and explore their Resources page
- University of Washington’s Intro to Data Science and Computing for data analysis will be a good start
- Explore this GitHub Link and try to read as much as you can
- Check out Measure for America to gain an understanding of how data can make a difference
- Read the free book – Field Guide to Data Sciences
- Religiously follow this infographic on how to become a data scientist
- Read this blog to master your R skills
- Read this blog to master your statistics skills
- Read this wonderful practical intro to data sciences by Zipfian Academy
- Try to complete this open source data science Masters program
- Do this Machine Learning course at Coursera by the co-founder Andrew Ng of Coursera himself
- By all means, complete this Data Science Specialization on Coursera, all nine courses, and the capstone
- If you lack computer science background or want to go towards programming side of the data sciences, try to complete this Data Mining Specialization from the Coursera
- Optional: depends on the industry you like to work with, you may want to check out these industry specific courses/links on data sciences, healthcare analytics – intro and specialization, education, performance optimization and general academic research
- To understand the deployment side of data science applications, this cloud computing specialization from the Coursera and Youtube Amazon Web Services and free training are a must to do
- Do these second-to-none courses on Mining Massive Datasets and Process Mining
- This link will lead you to 27 best data mining books for free
- Try to read Data Science Central once a day, articles like this can save you a lot of time and discussion in interviews
- Try to compete in as many Kaggle competitions as you can
- To put a cherry on the cake, these statistics driven courses will help you in differentiation from all other applicants – Inferential Statistics, Descriptive Statistics, Data Analysis and Statistics, Passion drive stats, and Making Sense of Data
- Follow the following on Twitter for Predictive Analytics: @mgualtieri, @analyticbridge, @douglaney, @HypatiaLeslieA, @hyounpark, @KDnuggets, and @anilbatra
- Follow the following on Twitter for Big Data and Data Sciences: Alistair Croll, Alex Popescu, @rethinkdb, Amy Heineike, Anthony Goldbloom, Ben Lorica, @oreillymedia., Bill Hewitt, Carla Gentry CSPO, David Smith, David Feinleib, Derrick Harris, DJ Patil, Doug Laney – Edd Dumbill, Eric Kavanagh, Fern Halper, Gil Press, Gregory Piatetsky, Hilary Mason, Jake Porway, James Gingerich, James Kobielus, Jeff Hammerbacher, Jeff Kelly, Jim Harris, Justin Lovell, Kevin Weil, Krish Krishnan, Manish Bhatt, Merv Adrian, Michael Driscoll, Monica Rogati, Neil Raden, Paul Philp, Peter Skomoroch, Philip (Flip) Kromer, Philip Russom, Paul Zikopoulos, Russell Jurney, Sid Probstein, Stewart Townsend, Todd Lipcon, Troy Sadkowsky, Vincent Granville, William McKnight, Yves Mulkers, Zeeshan Usmani, and Data Mufti.
The whole list will take 3 to 12 months to complete and will cost you absolutely nothing, and I can guarantee you that with this skills-set you really have to try very hard to remain jobless. Even if you complete half of it, send me a note and I will have something ready for you.
Ball is in your court, it does not matter where you are and how much you can afford, if you want to make at least four times higher the average income of your countrymen, this is the way to do it, at least for next 10 years (where we will be generating 20 TBs of data per year per person versus 1 TB of data per year per person in the last 10 years.)
For everyone else data sciences is an opportunity, for me it’s a passion.
I’ve recently published a book Kaggle for Beginners. I hope you will enjoy it.
You might also like


